TL;DR
HTML data can be messy and difficult to work with. Tools from the tidyverse (like dlpyr, purrr, and rvest) make this process much easier, althought creating clean data from HTML takes time and patience. Ad hoc testing can be used to quickly evaluate the accuracy of an HTML parsing function. Clean data is well worth the time and effort required to obtain/create it.
Getting Started
This post outlines the process of scraping and cleaning the scripts to every Friends TV episode. Subsequent posts will provide various analyses of the cleaned data. The data was scraped from this awesome site that contains links to the hand trascribed script for every episode. In an effort to meet suggested guidelines for ethical web scraping I emailed the site owner and received permission to scrape the scripts and provide this post as a form of how-to. I also used this great post for some guidance with the initial approach. With permission and guidance in hand, it’s time to dive into the data.
First, we need to load the neccessary packages. We’ll use rvest to scrape the data from the web and other packages from the tidyverse to clean up the data. I also always load magrittr separate because I often use the %<>% function which isn’t imported in tidyverse.
# Packages
library(tidyverse)
library(rvest)
library(stringr)
library(magrittr)
library(hrbrthemes)
library(ggalt)
library(ggpubr)
library(testthat)
# Set random seed
set.seed(35749)
# Plot settings
theme_set(theme_ipsum())Now that we’re set up and ready to go, let’s take a moment to think through what we need to do in order to build out this data set. 1. Download all scripts with identifying season and episode data 2. Parse all scripts into speaker and line 3. Clean up any errors 4. Celebrate good times
Seems simple enough. Let’s get started.
Download Scripts
Since we want to be respectful of the site we’re pulling data from, we need to make sure that we’re only scraping what we need as few times as possible. Ideally, we’d be able to pull the html for all episodes at once and then work off of our local copy to perfect the parsing of each episode without needing to re-ping the site for each new episode. With that in mind, I spent some time poking around the site to determine of there was a set structure for each episode url. My idea was that if there was a clear pattern to each url, I could write a function to manipulate the base url and pull each script at once. Unfortunately, there isn’t an easily replicable pattern in the urls - most contain a reference to the season and episode number and a short slug referencing the episode title.
# Page with links to all episode scripts
base_url <- "http://www.livesinabox.com/friends/scripts.shtml"
base_html <- read_html(base_url)
# Extract nodes related to episodes
episode_nodes <- base_html %>%
html_nodes("a")
# Filter nodes to only episodes (episodes are the only href containing 3+ digits in a row)
episode_urls <- episode_nodes %>%
html_attr("href")
episode_nodes <- episode_nodes[str_detect(episode_urls,
"\\d{3,}") &
!duplicated(episode_urls)]
episode_urls %<>% str_subset("\\d{3,}")
full_urls <- glue::glue("http://www.livesinabox.com/friends/{episode_urls}")
tibble(url = sample(full_urls, 5))## # A tibble: 5 x 1
## url
## <chr>
## 1 http://www.livesinabox.com/friends/season9/0922.html
## 2 http://www.livesinabox.com/friends/season8/815towbv.htm
## 3 http://www.livesinabox.com/friends/1006.shtml
## 4 http://www.livesinabox.com/friends/season6/602rhr.htm
## 5 http://www.livesinabox.com/friends/season2/207rofo.htmNotice that the url structure varies across seasons! However, all is not lost. The main landing page here contains links to each episode script. We can first scrape data from this page to get links to the script for every episode! In fact, we’ve already done that and we have the link to each episode stored in episode_urls. We also have the meta data associated with those links in episode_nodes.
episode_nodes is a xml_nodeset of length 228 containing the complete html for the link to each episode. This means we have access to the link title, which contains the episode title, season number, and episode number. We also have access to the link reference, which is a reference to the page with the html of the whole script (we’ve already extracted this as episode_urls). Now lets build out a function that will take the xml_node for each episode, extract the episode url and scrape the script associated with that url while also providing episode meta data (season number, episode number, and episode title).
scrape_script <- function(xml_node){
# Scrapes provided url and returns a tibble containing metadata and html_data
#
# Args:
# xml_node: xml_nodeset from rvest
#
# Returns:
# data.frame with the following columns:
# - season_num
# - episode_num
# - episode_title
# - html_data
# Set url for scraping
relative_url <- html_attr(xml_node, "href")
url <- glue::glue("http://www.livesinabox.com/friends/{relative_url}")
# Debugging
print(url)
# Read html
html_data <- read_html(url)
# Season and episode number
episode_title <- xml_node %>%
html_text %>%
str_replace_all('[\\n\\"\\"\\t]',
"") %>%
str_replace_all("[ ]+",
" ")
season_episode <- str_extract(episode_title,
"[0-9]{3,}") %>%
as.numeric
# Extract season and episode number
season_num <- season_episode %/% 100
episode_num <- season_episode %% 100
# Clean episode title
episode_title <- str_replace_all(episode_title,
"^E\\w+ [0-9]{3,}: ?| \\([0-9]\\)",
"")
# Final tibble output
tibble(season_num,
episode_num,
episode_title,
html_data = list(html_data))
}Note that this function returns a tibble containing episode metadata along with a list column containing the html from a single scraped page. Since we have a list of all episodes (episode_nodes) we can use purrr:map_df to create a tibble of the html data for all episodes.
# Scrape episodes and put in dataframe
friends_htmls <- map_df(episode_nodes,
scrape_script)glimpse(friends_htmls)## Observations: 228
## Variables: 4
## $ season_num <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ episode_num <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1...
## $ episode_title <chr> "The Pilot-The Uncut Version", "The One With The...
## $ html_data <list> [<html>, <html>, <html>, <html>, <html>, <html>...We’ve now created a tibble called friends_htmls that contains a single entry for each episode. Each row contains episode meta data and the full html for that episode. Step 1 of our outline is complete!
Parse Scripts
Now we’ve come to the tricky part of this process. If the html for each episode followed the same formatting standard, parsing the html would actually be fairly simple since we could write a single parser that would work seamlessly across all episodes. However, some poking around on the site quickly reveals that while there is a general pattern, some episodes definitely beat to the tune of their own drum. For example, take a look at The One Where Rachel Goes Back to Work and The One With Ross’s Inappropriate Song. This difference in structure makes it difficult to write a general parser for each episode. However, even with different html structures, there are some similarities among scripts that we can take advantage of.
First, in every script the speaker of each line is identified by the name of that speaker followed by a colon (ie Joey: This guy says hello, I wanna kill myself.). While the convention used for labeling the speaker varies (some are all caps, some are not) they all begin with a capital letter and they all have a colon before the actual line. Based on this, we can use a regular expression to extract the speaker and identify the associated line. Regular expressions can be a bit tricky at first, but Hadley Wickham and Garret Grolemund provide a great intro in the strings chapter of R for Data Science. The following parsing function is the result of quite a bit of trial and error, but it provides a good initial approach to parsing the scripts.
parse_script <- function(html_data, title = NULL){
# Parse html reference into dataframe with speaker and line columns
#
# Input:
# html_data: html reference to be parsed
# title: used for debugging and knowing which file is currently being parsed
#
# Returns:
# dataframe with speaker and line columns
# Print title if provided - used for debugging purposes
if (!is.null(title)) {
print(title)
}
# Extract script
script <- html_nodes(html_data, "p") %>%
html_text()
# Sepcial case for Season 9 Episode 7
if (length(script) == 0) {
script <- html_nodes(html_data, "pre") %>%
html_text()
}
# Handle times when script isn't broken out by lines
if (length(script) < 20) {
# Collapse script into single character vector
script <- str_c(script, collapse = " ")
# Remove new line characters
script %<>% str_replace_all("[::punct::]?\\n",
". ")
# Remove non dialogue
script %<>% str_replace_all('\\"|\\((.*?)\\)|\\[(.*?)\\]',
"")
# Identify speaker pattern
speaker_pattern <- "([MD][A-Za-z]{1,2}\\. )?[A-Z]{1}[\\w ]+: "
# Identify speaker name
speaker <- script %>%
str_extract_all(speaker_pattern) %>%
unlist %>%
str_replace_all("[\\n:]",
"")
# Identify the lines
script %<>% str_split(speaker_pattern) %>%
unlist
if (length(script) != length(speaker)) {
script <- script[-1]
}
} else {
# Identify dialogue lines
script <- script[str_detect(script, "^[\\w. ]+:")]
# Remove new line characters
script %<>% str_replace_all("\\n",
" ")
# Remove:
# escaped quotes
# text in parantheses (not dialogue)
# text in square brackets
script %<>% str_replace_all('\\"|\\(.*\\)|\\[(.*?)\\]',
"")
# Identify speaker pattern
speaker_pattern <- "^[\\w\\. ]+:"
# Identify speaker for each line
speaker <- str_extract(script,
speaker_pattern) %>%
str_replace(":",
"")
# Remove speaker from script
script %<>% str_replace(speaker_pattern,
"")
}
# Clean up any unnecessary white space
speaker %<>% str_trim()
script %<>% str_trim()
# Create dataframe
tibble(speaker,
line = script)
}This parsing function returns a tibble containing a single row for each line and columns for the speaker and the line itself. The next step is to apply this function over the html for each episode, parse the script and combine the resulting tibble into a single tibble representing all episodes. I’ve dabbled with purrr in the past, but this is where it really starts to shine. I’ve always been a fan of the apply family of functions in base R, and purrr is a nice, tidy, drop in replacement for those functions. Behold, the magic:
friends_scripts <- friends_htmls %>%
mutate(script = map(html_data, parse_script)) %>%
select(-html_data) %>%
# This is magic
unnest(script)
glimpse(friends_scripts)## Observations: 61,615
## Variables: 5
## $ season_num <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ episode_num <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ episode_title <chr> "The Pilot-The Uncut Version", "The Pilot-The Un...
## $ speaker <chr> "Written by", "Monica", "Joey", "Chandler", "Pho...
## $ line <chr> "Marta Kauffman & David Crane", "There's nothing...Combining purrr::map with dplyr::mutate creates a list column called script that contains a tibble of the parsed script for each episode. Using tidyr::unnest unpacks that list column and the resulting tibble is exactly what we want: a row for each line from each episode along with the speaker and episode specific data (season number, episode number, and episode title).
Now that we’ve parsed the scripts, let’s perform a couple of sanity checks to make sure that everything looks correct. First, we’ll look at the number of episodes and seasons we have to make sure we really got everything. We’ll also examine the distribution of lines per episode and the distribution of the number of characters in each speakers name.
# Define some functions that will be used a few times
data_integrity_plots <- function(friends_script_data){
# Creates a plot with the number of episodes per season, the distribution of
# lines per episode, and the distribution of nchar in speaker
#
# Args:
# friends_script_data: tibble of friends scripts with speaker, line, and
# metadata columns
#
# Returns:
# ggplot2 plot containing 3 plots - number of episodes per season, distribution
# of lines per episode, and distribution of nchar in speaker
# Number of episodes and seasons
episodes_per_season <- friends_script_data %>%
group_by(season_num) %>%
summarise(episodes = n_distinct(episode_num)) %>%
ggplot(aes(x = as.factor(season_num),
y = episodes)) +
geom_lollipop() +
labs(title = "Episodes per Season",
x = "Season",
y = "Number of Episodes",
caption = "*Note that two-part episodes are transcribed as single episodes.")
# Number of lines per episode
lines_per_episode <- friends_script_data %>%
group_by(season_num,
episode_num,
episode_title) %>%
count() %>%
ggplot(aes(x = n)) +
geom_histogram() +
labs(title = "Lines per Episode",
x = "Number of Lines",
y = "Count")
# Number of characters in speaker
nchar_speaker <- friends_script_data %>%
mutate(nchar_speaker = nchar(speaker)) %>%
ggplot(aes(x = nchar_speaker)) +
geom_histogram() +
labs(title = "Nchar Speaker",
x = "Number of Characters in Speaker",
y = "Count")
cowplot::plot_grid(episodes_per_season,
lines_per_episode,
nchar_speaker,
align = "h",
nrow = 1)
}
data_integrity_outliers <- function(friends_script_data){
# Identifies outliers in speaker column based on nchar and episode based on
# number of lines
#
# Args:
# friends_script_data: tibble of friends scripts with speaker, line, and
# metadata columns
#
# Returns:
# list of 2 tibbles containing specified outliers
episode_outliers <- friends_script_data %>%
group_by(season_num,
episode_num,
episode_title) %>%
count() %>%
ungroup() %>%
mutate(pct_rnk = percent_rank(n)) %>%
filter(pct_rnk < .01 | pct_rnk > .99) %>%
arrange(pct_rnk)
# Find outliers in nchar speaker
speaker_outliers <- friends_script_data %>%
group_by(speaker) %>%
summarise(nchar_speaker = nchar(unique(speaker)),
count = n(),
episodes = list(unique(episode_title))) %>%
mutate(pct_rnk = percent_rank(nchar_speaker)) %>%
filter(pct_rnk < .01 | pct_rnk > .95) %>%
arrange(pct_rnk)
list(episode_outliers,
speaker_outliers)
}data_integrity_plots(friends_scripts)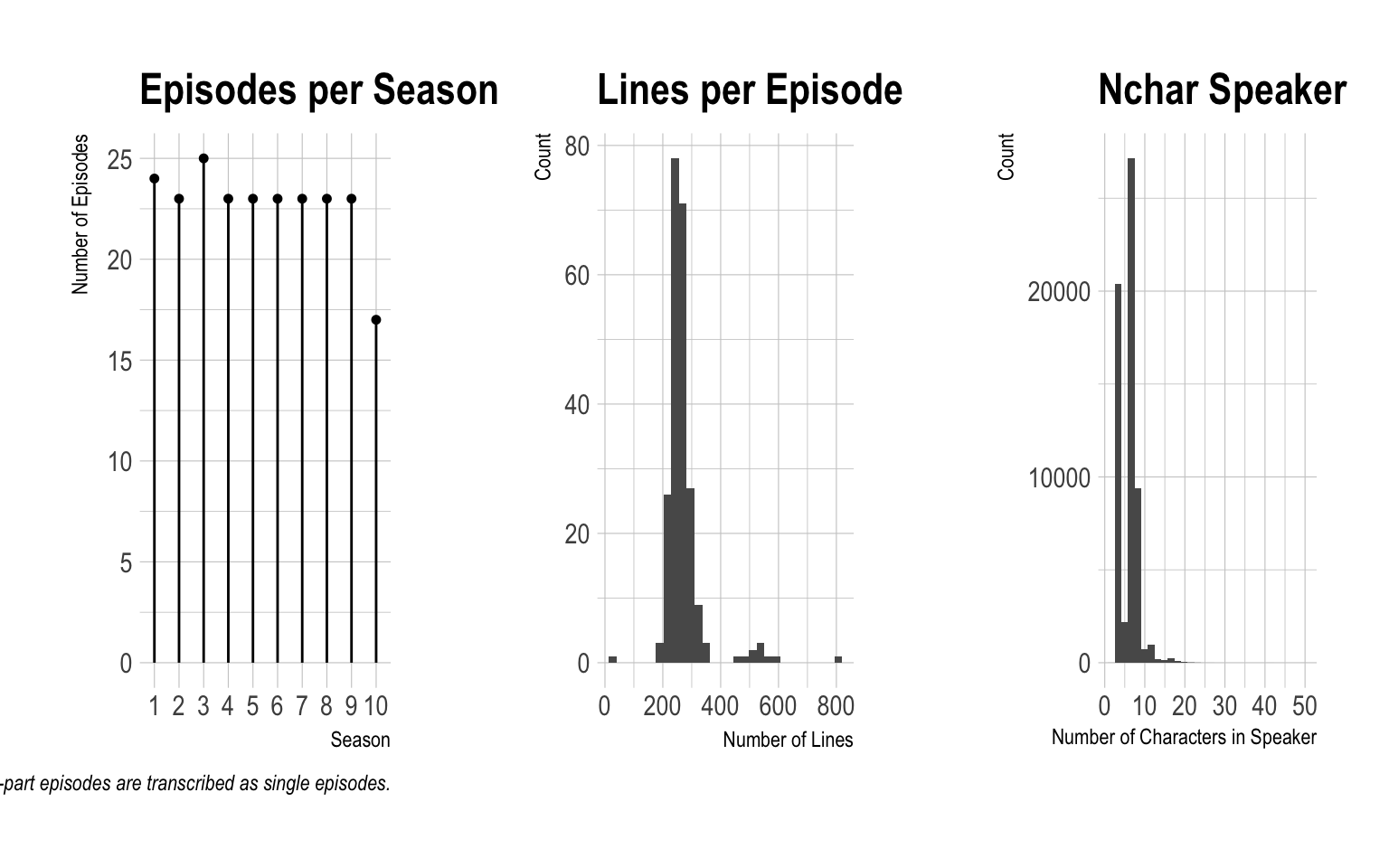
As evidenced by the plots above, it looks like we have all episodes represented. However, there appears to be a few major outliers when it comes to the number of lines per episode and the number of characters in speaker. Let’s take a look at those further to identify the outliers and determine if any action needs to be taken.
data_integrity_outliers(friends_scripts)## [[1]]
## # A tibble: 6 x 5
## season_num episode_num episode_title n pct_rnk
## <dbl> <dbl> <chr> <int> <dbl>
## 1 9. 15. The One With The Mugging 24 0.
## 2 1. 14. The One With The Candy Hearts 190 0.00441
## 3 7. 12. The One Where They're Up All Night 198 0.00881
## 4 10. 17. The Last One 561 0.991
## 5 9. 23. The One In Barbados 596 0.996
## 6 4. 23. The One With Ross's Wedding - The … 804 1.00
##
## [[2]]
## # A tibble: 60 x 5
## speaker nchar_speaker count episodes pct_rnk
## <chr> <int> <int> <list> <dbl>
## 1 PA 2 1 <chr [1]> 0.
## 2 TV 2 2 <chr [1]> 0.
## 3 All 3 304 <chr [113]> 0.00250
## 4 ALL 3 33 <chr [9]> 0.00250
## 5 Amy 3 119 <chr [2]> 0.00250
## 6 Ben 3 68 <chr [9]> 0.00250
## 7 BEN 3 5 <chr [1]> 0.00250
## 8 Bob 3 18 <chr [3]> 0.00250
## 9 Boy 3 1 <chr [1]> 0.00250
## 10 Cop 3 14 <chr [1]> 0.00250
## # ... with 50 more rowsWoah, The One With The Mugging currently contains only 24 lines. A quick visit to the webpage for that episode reveals that something on our end has gone terribly wrong. Let’s investigate and determine the problem. A good place to start is by stepping through the parsing function with the episode in question.
# Pull out html for problem episode
html_data <- friends_htmls %>%
filter(season_num == 9,
episode_num == 15) %$%
html_data %>%
.[[1]]
# Step through parsing function
# Extract script
script <- html_nodes(html_data, "p") %>%
html_text()
writeLines(script)## Chandler: (excited) Guys, guys, I've got great news! Guess what
Joey: Uh, ah, Monica's pregnant?!Monica: (shocked) Really? (She looks around, suddenly embarrassed)
## Let's get past the moment.Phoebe: What's your news?Chandler: Thank you. I got a job in advertising. (Everybody cheers)Monica: (hugging Chandler) Oh, honey, that's incredible!Phoebe: (inquisitive) Gosh, what's the pay like? (Everybody
## stares at her indignantly) Oh, come on people
(defending) come
## on, now, if I don't know who makes the most, how do I know who I like the most!
## (She looks at Joey) Hey Joey! (Joey winks at her)Chandler: Actually, it pays nothing. It's an internship.Joey: Oh, that's cool. We have interns at 'Days Of Our Lives'. Chandler: Right. So, it'll be the same except
less sex with you.
## (Joey nods)Ross: So, uh, what kinda stuff do you think they'll have you do there?Chandler: Well, it's a training program, but at the end, they hire the
## people they like.Phoebe: (enthusiastic) That's great.Chandler: Yeah, I mean, there's probably gonna be some ground work which
## will probably stink, you know, grown man getting people coffee is a little humiliating
##
## (At the same time, Gunther puts down a cup of coffee in front of Chandler)Chandler: (grinning awkwardly) Humiliating and noble!
## (Gunther shoots a nasty look at him while leaving)Ross: You know, if I didn't already have a job, I think, I would have
## been really good in advertising.Monica: Ross, you did not come up with "got milk?"Ross: Yes, I did, I did! (He turns to Joey, disappointed)
## I should have written it down!
##
## [Scene: Monica and Chandler's Apartment, Monica sits at the table
## reading the mail]Monica: Wow, that's a big cable bill! Huh, you don't have a job, but
## you have no problem ordering porn
on a Saturday afternoon?! (shocked)
## I was in the house! Ross: (entering) Hey, uhm, Phoebe didn't by any chance mention
## that
Monica:
that she was the huge guy that mugged you? Yah. Ross: I see. You didn't happen to tell
Monica:
everybody we know? Yeah.Ross: Great. Thanks! (He leaves)Aha! It looks like we’ve found the bug in the first part part of the parsing script. For some reason, we’re not grabbing the whole episode from the html. A quick visit back to the episode website using selector gadget reveals that the script isn’t entirely contained within <p> tags. For this particular episode, we have to use the <body> tag to get everything. Armed with this new knowledge, the challenge now is to best determine how to deal with this special case.
When it comes to handling special cases in parsing there are two distinct approaches that can be taken. So far, we’ve handled each case on it’s own, essentially writing a new parser for each possible format/structure. On the other hand, we could write a single parser that applies to the majority of cases and then work to format special cases to meet the assumptions of that parser. I spent a significant amount of time trying to get this second approach to work by extracting the <body> of every episode and parsing that. However, I eventually realized that the results are much cleaner if I continue to parse using the <p> tags when possible and only use <body> when <p> fails.
While re-configuring the parsing function it will be helpful to quickly spotcheck the performance using a subset of episodes that contain typical episode formatting and edge cases. We can either perform these spot checks manually as we make updates to the parsing function, or we can write some quick tests to evaluate the performance of the parser using the testthat package.
A quick note on
testthat: It looks like it has some built in functionality to run interactively within RStudio (given the fact that there is an object calledRstudioReporterin the package). However, I have been unable to find documentation on how to usetestthatin the optimal way from RStudio. The default implementation, which uses theStopReporter, will throw an error on any failed test. Due to this behavior, the full test suite will not run if any test prior to the final test fails.
# Define test data with a few html scripts
parse_test_data <- friends_htmls %>%
filter((season_num == 9 & episode_num == 15) |
(season_num == 9 & episode_num == 7) |
(season_num == 1 & episode_num == 9) |
(season_num == 2 & episode_num == 18) |
(season_num == 3 & episode_num == 3) |
(season_num == 1 & episode_num == 2) |
(season_num == 10 & episode_num == 4) |
(season_num == 3 & episode_num == 11) |
(season_num == 1 & episode_num == 14))
parse_tests <- function(parse_fun){
# Tests parse_fun meets certain expectations when evaluated on test_data
parse_results <- parse_test_data %>%
mutate(script = map2(html_data, episode_title, parse_fun)) %>%
select(-html_data) %>%
unnest(script)
with_reporter(SummaryReporter, {
test_that("All episodes present in parsed data", {
difference <- setdiff(unique(parse_test_data$episode_title),
unique(parse_results$episode_title))
expect_true(length(difference) == 0,
info = glue::glue("Missed: {difference}"))
})
test_that("Number of lines per episode appears correct", {
line_counts <- parse_results %>%
group_by(episode_title) %>%
count()
# Low line counts
line_counts %>%
mutate(test = map(n, ~expect_true(n >= 190,
info = glue::glue("Episode: {episode_title}\t Lines: {n}"))))
# High line counts
line_counts %>%
mutate(test = map(n, ~expect_true(n <= 200,
info = glue::glue("Episode: {episode_title}\t Lines: {n}"))))
})
# Test correct speaker parsing
test_that("Speaker has been parsed correctly", {
# Check that Mr. Mrs. and Dr. distinctions are correctly included
expect_match(parse_results$speaker,
"[MD][A-Za-z]{0,2}\\.",
all = FALSE)
# Check that fireman characters are included
expect_match(parse_results$speaker,
"Fireman",
all = FALSE)
# Check that multi-speaker lines are included
expect_match(parse_results$speaker,
" And ",
all = FALSE)
# Check that certain edge phrases aren't considered speakers
expect_false(any(str_detect(parse_results$speaker,
"Signs")))
expect_false(any(str_detect(parse_results$speaker,
"Yourself")))
expect_false(any(str_detect(parse_results$speaker,
"Seven Sisters")))
})
})
}The following updated parsing function is the result of a feedback loop involving updating parse_script, running the test suite in parse_tests, and further adjusting parse_script.
parse_script <- function(html_data, title = NULL){
# Parse html reference into dataframe with speaker and line columns
#
# Input:
# html_data: html reference to be parsed
# title: used for debugging and knowing which file is currently being parsed
#
# Returns:
# dataframe with speaker and line columns
# Print title if provided
# if (!is.null(title)) print(title)
odd_episodes <- c("The One With The Mugging",
"The One Where Rachel Goes Back To Work",
"The One With Ross's Inappropriate Song",
"The One Where Dr. Remoray Dies",
"The One After the Superbowl",
"The One Where Joey Moves Out",
"The One Where Eddie Moves In",
"The One Where Eddie Won't Go",
"The One Where Old Yeller Dies",
"The One With The Two Parties",
"The One With The Chicken Pox",
"The One With The Prom Video",
"The One Where Ross and Rachel...You Know",
"The One With The Bullies",
"The One With Barry and Mindy's Wedding",
"The One With Phoebe's Dad")
# Handle the weird cases
if (title %in% odd_episodes) {
script <- html_nodes(html_data, "body") %>%
html_text()
} else {
# Extract script
script <- html_nodes(html_data, "p") %>%
html_text()
}
# Remove anything in parentheses or square brackets
brackets <- regex("\\((.*?)\\)|\\[(.*?)\\]|\\{(.*?)\\}",
dotall = TRUE)
script %<>% str_replace_all(brackets, "")
# Remove unicode character \u0085
remove_unicode <- regex("\\u0085")
script %<>% str_replace_all(remove_unicode,
" ")
# Remove unicode character \\u0092
remove_unicode <- regex("\\u0092|\\u0096")
script %<>% str_replace_all(remove_unicode,
"")
# Replace multiple spaces with single space
script %<>% str_replace_all(" +", " ")
# Replace multiple new line characters with a single newline
script %<>% str_replace_all("[\\n\\t]+", "\n")
# Remove quote characters
script %<>% str_replace_all("['\"]", "")
# Handle weird episodes
if (title %in% odd_episodes) {
speaker_pattern <- regex("([.?!]|\\n) ?([MD][A-Za-z]{1,2}\\. )?[A-Z]{1}[\\w,'\\-& ]+:( |\\n)?")
# Extract speaker
speaker <- script %>% str_extract_all(speaker_pattern) %>%
unlist()
# Split script
line <- script %>% str_split(speaker_pattern) %>%
unlist
# Remove leading line (not associated with speaker)
line <- line[-1]
} else {
# speaker_pattern <- regex("([MD][A-Za-z]{1,2}\\. )?[A-Z]{1}[\\w,'\\-&. ]+:( |\\n)?")
speaker_pattern <- regex("^[\\w\\., ]+:")
script %<>% str_subset(speaker_pattern)
speaker <- str_extract_all(script,
speaker_pattern)
line <- str_replace(script,
speaker_pattern,
"")
}
# Clean up lines and speaker
speaker_remove <- regex('\\"| # remove quotes
\\n| # remove newline
:| # remove semicolon
^[.?!] # remove leading punctuation',
comments = TRUE)
speaker %<>% str_replace_all(speaker_remove,
"") %>%
str_trim() %>%
str_to_title()
line_remove <- regex('\\" | # remove quotes
Crazy\\ For\\ Friends.*$ # Crazy For Friends endings',
comments = TRUE,
dotall = TRUE)
line %<>% str_replace_all(line_remove,
"") %>%
str_replace_all("\\n",
" ") %>%
str_trim()
tibble(speaker,
line)
}
parse_tests(parse_script)## ..........1......
## ══ Failed ═══════════════════════════════════════════════════════════════════════
## ── 1. Error: Number of lines per episode appears correct (@<text>#40) ──────────
## Evaluation error: n <= 200 isn't true.
## Episode: The One Where Chandler Can't Remember Which Sister Lines: 295.
## 1: line_counts %>% mutate(test = map(n, ~expect_true(n <= 200, info = glue::glue("Episode: {episode_title}\t Lines: {n}")))) at <text>:40
## 2: withVisible(eval(quote(`_fseq`(`_lhs`)), env, env))
## 3: eval(quote(`_fseq`(`_lhs`)), env, env)
## 4: eval(quote(`_fseq`(`_lhs`)), env, env)
## 5: `_fseq`(`_lhs`)
## 6: freduce(value, `_function_list`)
## 7: withVisible(function_list[[k]](value))
## 8: function_list[[k]](value)
## 9: mutate(., test = map(n, ~expect_true(n <= 200, info = glue::glue("Episode: {episode_title}\t Lines: {n}"))))
## 10: mutate.tbl_df(., test = map(n, ~expect_true(n <= 200, info = glue::glue("Episode: {episode_title}\t Lines: {n}"))))
## 11: mutate_impl(.data, dots)
##
## ══ DONE ═════════════════════════════════════════════════════════════════════════
## No-one gets it right on their first tryOnce we have a parsing function that passes all our tests, we can run it over the full data again to generate an updated version of friends_scripts.
friends_scripts <- friends_htmls %>%
mutate(script = map2(html_data, episode_title, parse_script)) %>%
select(-html_data) %>%
unnest(script)Now that we have updated friends_scripts, let’s check the integrity of the data using the functions we defined earlier.
data_integrity_plots(friends_scripts)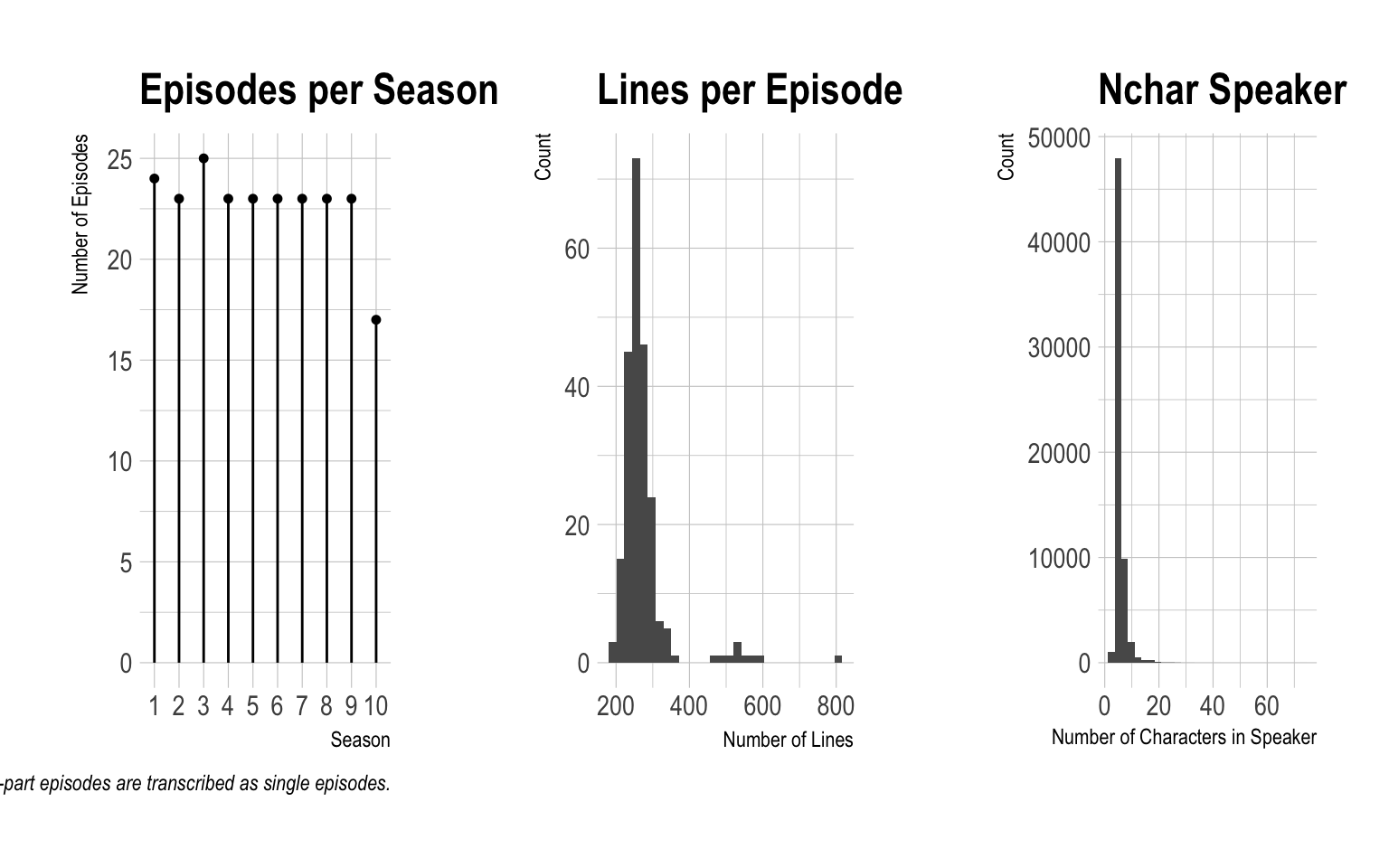
integrity_tbls <- data_integrity_outliers(friends_scripts)
integrity_tbls[[2]] %>%
filter(pct_rnk > .5) %>%
unnest(episodes) %>%
arrange(-nchar_speaker, count)## # A tibble: 49 x 5
## speaker nchar_speaker count pct_rnk episodes
## <chr> <int> <int> <dbl> <chr>
## 1 I Was Living On The Street … 73 1 1.000 The One With …
## 2 Everyone Almost Simultaneou… 42 1 0.999 The One With …
## 3 Youre Not Supposed To Say L… 40 1 0.998 The One With …
## 4 Monica, Chandler, Phoebe, A… 36 1 0.996 The One With …
## 5 Chandler, Monica, Joey, And… 34 1 0.995 The One With …
## 6 Now, I Really Have To Get L… 33 1 0.994 The One With …
## 7 Phoebe, Ross, Chandler, And… 32 1 0.992 The Pilot-The…
## 8 Wow, Hey, Heres What We Gon… 32 1 0.992 The One With …
## 9 Even More Humiliating Than … 31 1 0.989 The One With …
## 10 You Didnt Happen To Tell Mo… 31 1 0.989 The One With …
## # ... with 39 more rowsThe parsing still isn’t quite perfect. For example, The One With Ross’s Inappropriate Song has an instance where speaker was parsed as I Dont Know What To Say Ross. Given the varied formatting of each episode, it’s difficult to write a parser that correctly distinguishes real speakers but doesn’t identify this value as a speaker. However, it appears that for the most part our parsing function has performed well.
Clean Scripts
Now that we have a nice dataset, it’s tempting to call our work complete. However, there’s still some work to be done. For example, lines that are obviously not actually lines should be removed and consideration needs to be given to how to handle lines with multiple speakers.
We’ll start by removing any observations that aren’t actually lines and cleaning up the speaker column. We’ll identify these lines by looking at the unique speaker values from least to most common and from longest to shortest.
friends_scripts %>%
mutate(nchar = str_length(speaker)) %>%
group_by(speaker,
nchar) %>%
mutate(n = n()) %>%
arrange(n, -nchar, speaker)# Remove bad lines
to_remove <- "Aired|Copyright|Note|Directed|Written By|Teleplay|Transcrib|Written|Story|Scene|Recent Updates|Adjustments"
to_replace <- "CLOSINGCREDITS|CLOSING CREDITS|Gary Halvorson|OPENINGTITLES|OpeningTitles|OPENING TITLES|Opening Titles"
# Remove lines that aren't lines
friends_scripts %<>% filter(!str_detect(speaker,
to_remove))
# Clean up speaker column
friends_scripts %<>% mutate(speaker = str_replace_all(speaker,
to_replace,
""))
# String trim speaker
friends_scripts %<>% mutate(speaker = str_trim(speaker,
side = "both"))Now that we’ve cleaned things up a bit, let’s investigate to determine if there are any nested lines that need to be broken out.
# Check for any nested lines
friends_scripts %>%
filter(str_detect(line,
"[A-Za-z]+:"))There are very few, so for now we’ll leave them. Let’s also see if we can address instances where multiple people say the same line (ie Everyone, All, Both, Joey and Chandler, etc).
# Add line number to each episode in order to later identify lines spoken at the same time
friends_scripts %<>%
group_by(season_num, episode_num) %>%
mutate(line_num = row_number())
# Identify the 6 main characters
the_friends <- c("Chandler",
"Rachel",
"Ross",
"Monica",
"Joey",
"Phoebe")
multi_speaker_separator <- function(speaker){
# Takes speaker vector and separates out multiple speakers
# Split on And and ,
speaker <- str_split(speaker,
" And |, ",
simplify = TRUE)
if (length(speaker) == 1) {
# Cases where speaker is ALl or Everyone
# This isn't perfect - All often means everyone except for the individual who just spoke
if (speaker == "All" | speaker == "Everyone") {
speaker <- the_friends
}
}
# Ensure speaker is character vector
speaker %<>% as.character()
# Clean up speaker
speaker %<>% str_replace_all("^And|,",
"") %>%
str_trim()
speaker
}
friends_scripts %<>%
mutate(speaker = map(speaker, multi_speaker_separator)) %>%
unnest(speaker)The final step we’ll take for now is to standardize the main characters names. There are instances where instead of using the full name certain speakers are identified with shortened nicknames (ie Rach instead of Rachel).
friends_scripts %<>%
mutate(speaker = case_when(speaker == "Rach" ~ "Rachel",
speaker == "Phoe" ~ "Phoebe",
speaker == "Mnca" ~ "Monica",
speaker == "Chan" ~ "Chandler",
TRUE ~ speaker))Now that the most frequent speaker abbreviations have been adjusted, let’s validate the following assumption: the six main characters should show up in the top 10 speakers for each episode.
friends_scripts %>%
group_by(season_num,
episode_num) %>%
count(speaker) %>%
top_n(10, n) %>%
group_by(speaker) %>%
summarise(n = n()) %>%
arrange(-n) %>%
head(6)## # A tibble: 6 x 2
## speaker n
## <chr> <int>
## 1 Chandler 227
## 2 Joey 227
## 3 Monica 227
## 4 Phoebe 227
## 5 Rachel 227
## 6 Ross 227Based on this view, all main characters show up in the top ten characters for each episode. For now, our data cleaning work is done.
Celebrate
Whew. Pat yourself on the back. Take a breather. We made it! At this point, we’ll call our work complete for now. There are still some data cleaning tasks that can be performed (standardizing mispelled speaker names and dealing with nested lines) but we have a resonably clean data set that provides a foundation for future analyses. At some point I may revisit this to clean the data up a bit more, but for now we’ll accept what we have and move on.
Our final friends_scripts is a tibble with 6 columns and 63890 rows containing the script from every Friends episode. The next post will investigate this dataset by looking at the sentiment of Friends over time, both as a whole and by individual characters. To enable that future analysis without the need to rescrape and perform everything we’ve done here, let’s save friends_scripts so we can load it in the future.
friends_scripts %<>% select(season_num,
episode_num,
episode_title,
speaker,
line,
line_num) %>%
ungroup()
saveRDS(friends_scripts,
file = "../../data/friends/friends_scripts.Rds")